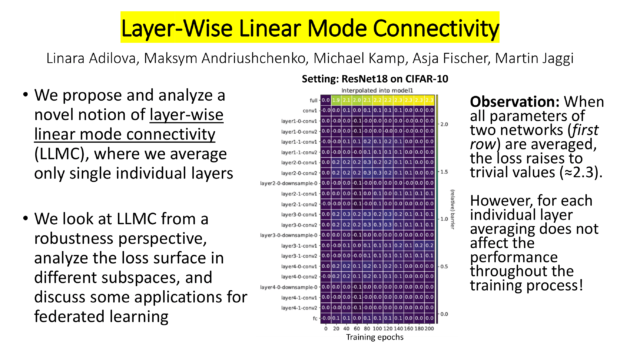
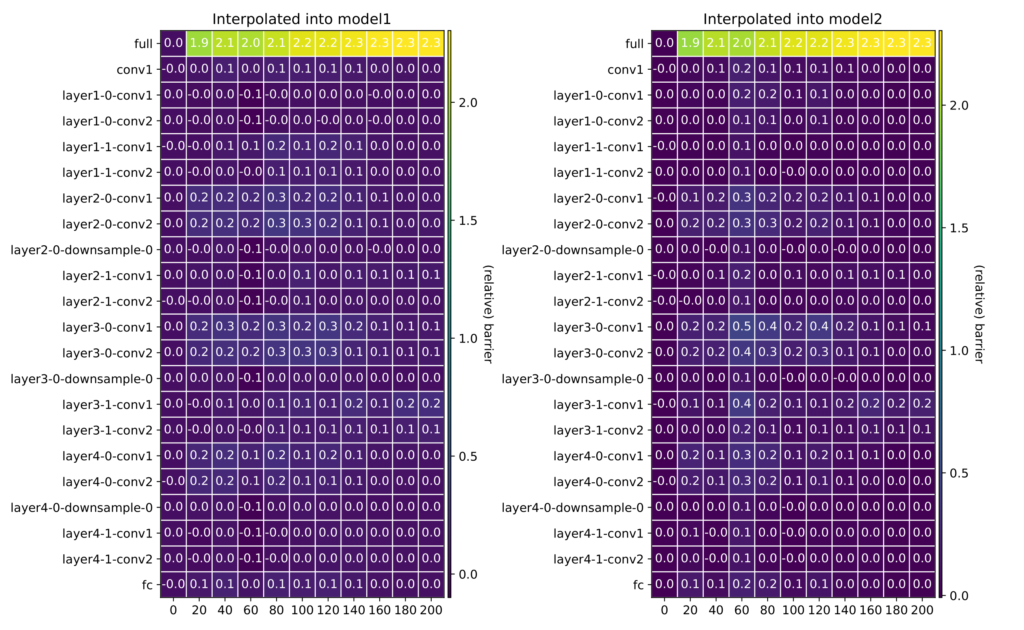
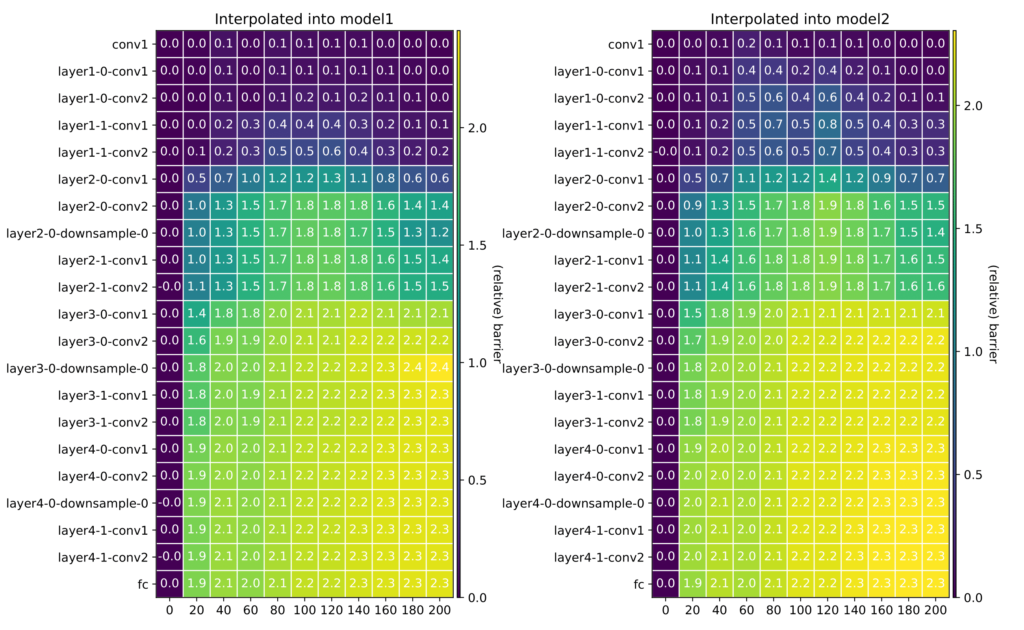
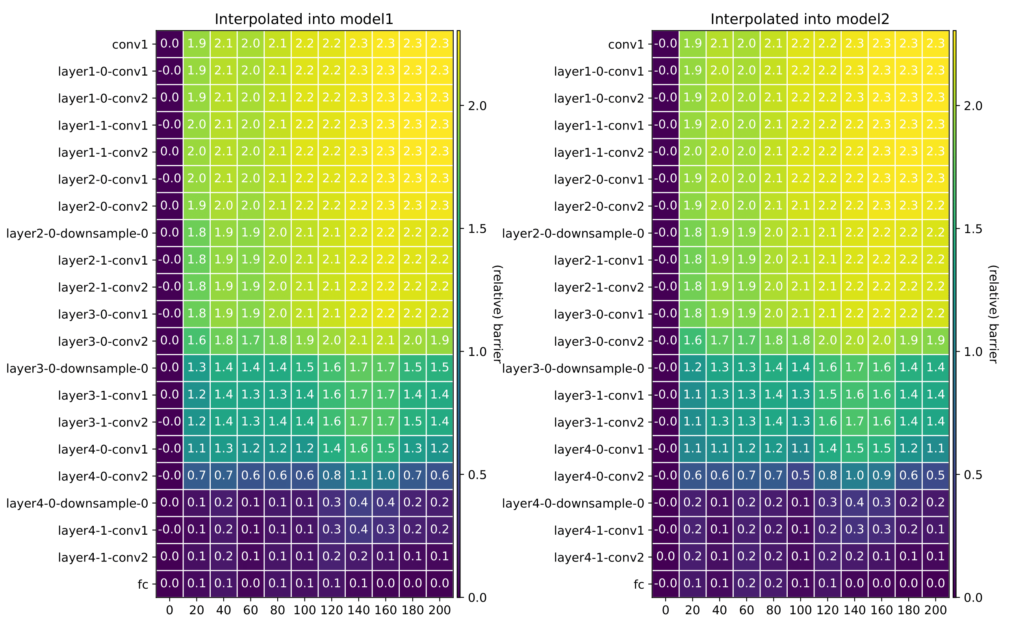
Can we train high-quality models on distributed, privacy-sensitive data without compromising security? Federated learning aims to solve this problem by training models locally and aggregating updates, but there’s a catch—shared model parameters or probabilistic predictions (soft labels) still leak private information. Our new work, “Little is Enough: Boosting Privacy by Sharing Only Hard Labels in Federated Semi-Supervised Learning,” presents an alternative: federated co-training (FedCT), where clients share only hard labels on a public dataset.
This simple change significantly enhances privacy while maintaining competitive performance. Even better, it enables the use of interpretable models like decision trees, boosting the practicality of federated learning in domains such as healthcare.
This work was presented at AAAI 2025 and was done in collaboration with Amr Abourayya, Jens Kleesiek, Kanishka Rao, Erman Ayday, Bharat Rao, Geoffrey I. Webb, and myself.
Federated Learning: A Privacy Illusion?
Federated learning (FL) is often praised for enabling collaborative model training without centralizing sensitive data. However, model parameters can still leak information through various attacks, such as membership inference and gradient inversion. Even differentially private FL, which adds noise to mitigate these risks, suffers from a trade-off—stronger privacy means weaker model quality.
Another alternative, distributed distillation, reduces communication costs by sharing soft labels on a public dataset. While this improves privacy compared to sharing model weights, soft labels still expose patterns that can be exploited to infer private data.
This brings us to an essential question: Is there a way to improve privacy without sacrificing model performance?
A Minimalist Solution: Federated Co-Training (FedCT)
Instead of sharing soft labels, FedCT takes a radical yet intuitive approach: clients only share hard labels—definitive class assignments—on a shared, public dataset. The server collects these labels, forms a consensus (e.g., majority vote), and distributes the pseudo-labels back to clients for training.

This approach has three key advantages:
- Stronger Privacy – Hard labels leak significantly less information than model parameters or soft labels, drastically reducing the risk of data reconstruction attacks.
- Supports Diverse Model Types – Unlike standard FL, which relies on neural networks for parameter aggregation, FedCT works with models like decision trees, rule ensembles, and gradient-boosted decision trees.
- Scalability – Since only labels are communicated, the approach dramatically reduces bandwidth usage—by up to two orders of magnitude compared to FedAvg!

Empirical Results: Privacy Without Performance Trade-Offs
We evaluated FedCT on various benchmark datasets, including CIFAR-10, Fashion-MNIST, and real-world medical datasets like MRI-based brain tumor detection and pneumonia classification.
Key Findings:
- Privacy wins: FedCT achieves near-optimal privacy (VUL ≈ 0.5), making membership inference attacks no better than random guessing.
- Competitive accuracy: FedCT performs as well as, or better than, standard FL and distributed distillation in most scenarios.
- Interpretable models: It successfully trains decision trees, random forests, and rule ensembles, unlike other FL approaches.
- Robust to data heterogeneity: Even when clients have diverse (non-iid) data, FedCT performs comparably to FedAvg.

Notably, FedCT also shines in fine-tuning large language models (LLMs), where its pseudo-labeling mechanism outperforms standard federated learning.
Privacy Through Simplicity
The core idea behind FedCT is beautifully simple: share less, retain more privacy. By moving away from parameter sharing and probabilistic labels, we mitigate privacy risks while keeping performance intact.
That said, some open questions remain:
- How does the choice of public dataset impact FedCT’s effectiveness?
- Can we further refine the consensus mechanism for extreme data heterogeneity?
- How does FedCT behave when applied to real-world hospital collaborations?
For now, our results suggest that in federated learning, little is enough. Sharing only hard labels provides a surprisingly strong privacy-utility trade-off—especially in critical applications like healthcare.
For more details, check out our paper on arXiv or our GitHub repository.
Stay tuned for more research updates from our Trustworthy Machine Learning group at IKIM and Ruhr University Bochum!